Migration cloud : définition, étapes et exemples concrets
Définition de la migration cloud, enjeux pour les entreprises, modèles (IaaS, PaaS, SaaS, hybride), étapes clés, risques à anticiper et bonnes pratiques pour réussir un projet de migration.
Qu’est-ce que la migration cloud ?
La migration cloud désigne le fait de déplacer tout ou partie d’un système d’information vers une plateforme cloud, qu’il s’agisse d’applications, de données ou d’infrastructures complètes. Le point de départ peut être un data center interne, un hébergeur historique ou même un autre fournisseur cloud. L’objectif n’est pas uniquement de changer de lieu d’hébergement, mais de tirer parti d’un modèle où les ressources sont plus flexibles, les services plus intégrés et la capacité d’évolution plus rapide.
Une migration cloud réussie ne consiste pas à “déplacer les serveurs dans le cloud” à l’identique, mais à concevoir une architecture qui améliore réellement la résilience, la sécurité et la performance opérationnelle. C’est cette dimension d’architecture qui distingue un simple lift and shift d’un projet de transformation maîtrisé.
Pourquoi les entreprises migrent vers le cloud ?
Les motivations les plus fréquentes ne se résument plus au coût. Les entreprises migrent vers le cloud pour réduire leur dette technique, se libérer de cycles de renouvellement matériel lourds, gagner en agilité pour déployer de nouvelles versions d’applications, renforcer la sécurité ou répondre à des enjeux de résilience et de continuité d’activité.
Certaines souhaitent également s’aligner sur un modèle de consommation plus lisible avec la capacité à ajuster les ressources, à activer des services managés (bases de données, files de messages, services d’authentification), à disposer d’une sauvegarde de données externalisée ou d’un plan de reprise d’activité plus industriel.
Dans la pratique, la plupart des organisations ne basculent pas tout leur système d’information dans le cloud. Elles s’orientent vers des architectures hybrides, où certaines briques restent sur site pour des raisons de latence, de dépendance à un équipement ou de contraintes réglementaires, tandis que d’autres migrent vers une plateforme cloud pour bénéficier d’un meilleur niveau de service.
Les différents modèles de migration cloud
On parle de migration cloud, mais derrière ce terme se cachent plusieurs modèles possibles, qui ont chacun leurs avantages et leurs limites.
-
Le modèle IaaS (Infrastructure as a Service) consiste à retrouver dans le cloud des ressources proches d’un data center classique :machines virtuelles, réseaux, stockage. Il permet de reproduire une architecture existante avec un contrôle fin, mais nécessite de conserver une grande partie des opérations d’administration.
-
Le PaaS (Platform as a Service) va plus loin en confiant au fournisseur la gestion de composants standardisés : bases de données managées, services de messagerie, fonctions serverless, orchestrateurs de conteneurs. L’entreprise se concentre davantage sur la logique applicative que sur l’infrastructure sous-jacente.
-
Le SaaS (Software as a Service) correspond, lui, à l’utilisation de logiciels fournis directement sous forme de service : CRM, messagerie, collaboration, solution de téléphonie, ERP en mode cloud. Dans ce cas, il ne s’agit plus de migrer une infrastructure, mais de déplacer un usage vers une solution déjà hébergée.
En pratique, la migration cloud combine souvent ces trois modèles, avec une forte dimension hybride : une partie du système reste on-premise, une autre bascule en IaaS ou PaaS, une troisième passe en SaaS.
Exemples de scénarios de migration cloud
Une migration cloud peut porter sur des périmètres très différents. Une entreprise peut, par exemple, décider de déplacer ses serveurs de fichiers, ses environnements de test et son application métier principale vers une plateforme IaaS, tout en conservant localement un applicatif lié à un atelier de production qui dépend d’équipements industriels spécifiques.
Dans un autre scénario, la priorité peut être la messagerie et les outils collaboratifs, qui migrent vers une solution SaaS, tandis que les bases de données critiques et certaines applications métiers basculent en PaaS pour bénéficier de services managés hautement disponibles.
Il existe également des projets centrés sur le data center lui-même : migration de serveurs physiques vers des machines virtuelles en cloud, démantèlement d’une salle informatique vieillissante, ou réhébergement d’applications historiques dans un environnement plus résilient. Dans ce contexte, la migration cloud est autant un projet d’infrastructure qu’un projet de rationalisation du patrimoine applicatif.
Les étapes clés d’un projet de migration cloud
Quel que soit le périmètre choisi, les projets de migration suivent généralement une trame commune.
La première étape est la cartographie : identifier les applications, leurs dépendances techniques, leurs flux réseau, les volumes de données, les contraintes horaires et les exigences de conformité. Cette cartographie permet de regrouper les composants qui doivent migrer ensemble et de distinguer les services facilement découplables.
Vient ensuite la définition des objectifs : réduction de la dette technique, amélioration de la disponibilité, renforcement de la sécurité, simplification des sauvegardes, optimisation des coûts, ouverture à de nouveaux usages. Cette clarification permet d’éviter les migrations “par principe” et d’aligner le projet sur des bénéfices concrets.
Une fois ces éléments posés, l’architecture cible est définie : choix du ou des fournisseurs cloud, arbitrage entre IaaS, PaaS et SaaS, schéma d’interconnexion réseau, politique de sauvegarde, plan de reprise d’activité. Dans cette phase, la qualité de la connexion entre sites et cloud, via un VPN d’entreprise ou des liens fibre optique dédiée, joue un rôle déterminant sur la performance finale.
Les organisations qui réussissent leurs migrations commencent généralement par un pilote représentatif. Il s’agit d’un ensemble limité d’applications ou d’environnements, sur lequel sont testées la performance, la sécurité, les sauvegardes et les procédures d’exploitation. Ce pilote sert de référence avant de généraliser la démarche à d’autres lots applicatifs.
C’est aussi à ce stade qu’un modèle Zero Trust doit être posé, car migrer vers le cloud sans repenser la sécurité constitue un risque majeur : le pilote permet justement de valider les accès, les cloisonnements et les contrôles avant de généraliser la démarche à d’autres lots applicatifs.
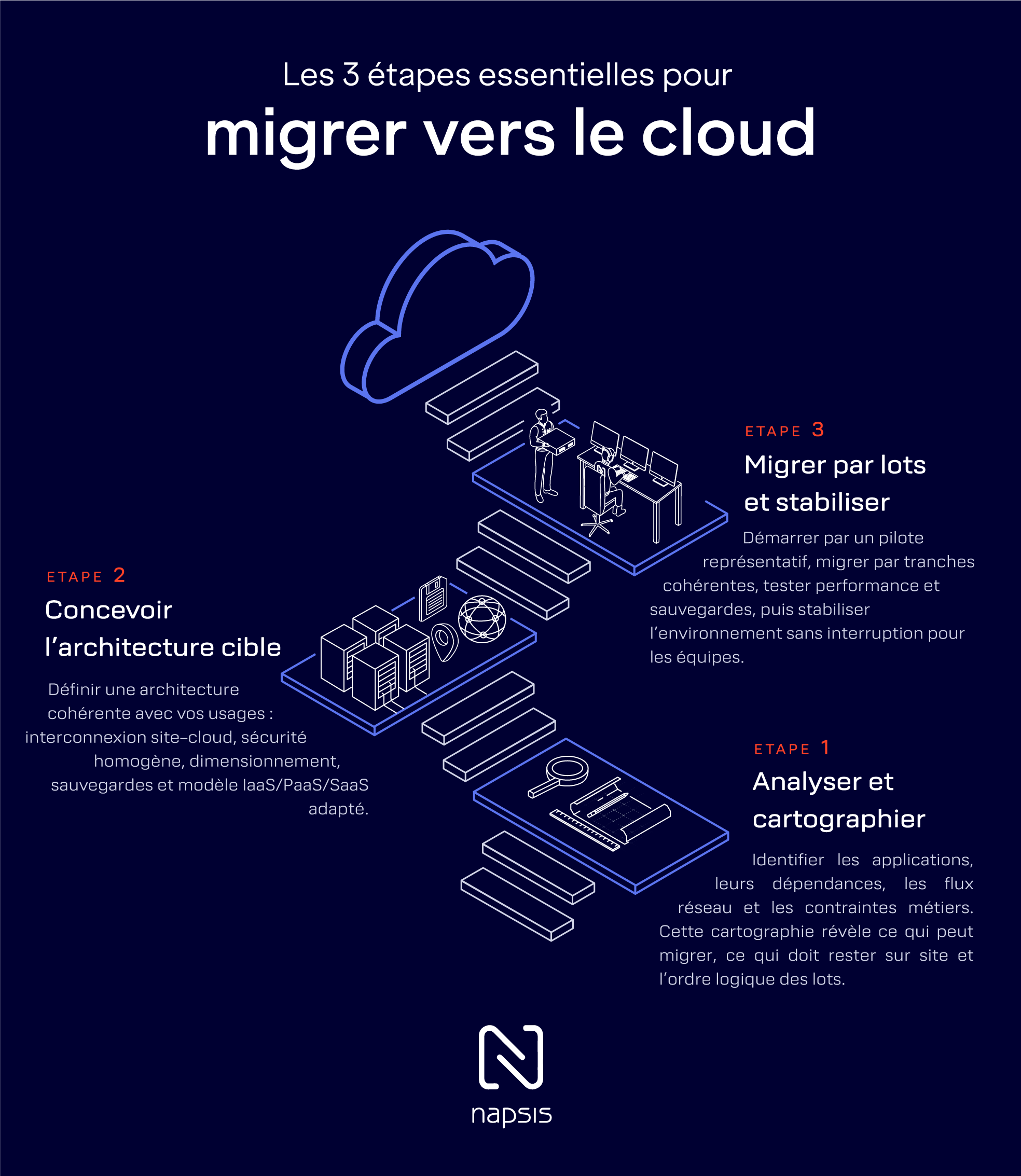
Les trois étapes clés d’une migration cloud : analyse de l’existant, conception de l’architecture cible et migration progressive avec phase de stabilisation.
Risques et points de vigilance de la migration dans le cloud
Un projet de migration cloud comporte des risques spécifiques. Le premier tient à la sous-estimation des dépendances : une application qui semble autonome peut en réalité reposer sur un service local, une base partagée, un connecteur réseau ou un processus métier implicite. Ces dépendances mal identifiées conduisent à des interruptions ou à une dégradation de la qualité de service lors de la bascule.
La performance est un autre point de vigilance majeur. Une application peut être fonctionnelle mais devenir trop lente si la latence augmente ou si les ressources ne sont pas correctement dimensionnées. Le fait de déplacer une base de données ou un serveur applicatif vers le cloud modifie la topologie réseau et peut exposer des limitations d’I/O ou de bande passante jusque-là invisibles.
Les coûts constituent également un risque. Le modèle à l’usage est attractif, mais il peut surprendre si les ressources ne sont pas ajustées, si les environnements de test restent allumés en permanence ou si les flux sortants (egress) ne sont pas maîtrisés. La discipline FinOps permet de piloter ces aspects de manière méthodique.
Enfin, la sécurité doit rester homogène entre les environnements. Une politique de filtrage incomplète, une identité fragmentée, des comptes administrateurs non rationalisés, des sauvegardes dispersées ou des journaux non centralisés peuvent créer des angles morts.
Migration cloud, réseau et téléphonie
La migration cloud n’a pas uniquement un impact sur les applications métier. Elle touche aussi la qualité de la voix, de la visio et des outils collaboratifs. Un projet mal anticipé peut entraîner une dégradation de la qualité perçue, alors même que le lien Internet n’a pas changé.
La maîtrise de la latence, la segmentation des flux, la priorisation de certains usages et la capacité à s’appuyer sur un lien fixe de qualité, comme une fibre dédiée FTTO, sont des facteurs essentiels. Lorsqu’une entreprise utilise déjà une téléphonie IP ou des outils de communication unifiée, la migration cloud doit être pensée en cohérence avec ces usages.
Bonnes pratiques pour réussir une migration cloud
Les bonnes pratiques ne garantissent pas l’absence d’imprévu, mais elles réduisent fortement le risque. Les plus structurantes sont celles qui concernent la méthode :
- cartographier avant de migrer,
- définir des objectifs clairs,
- valider l’architecture sur un pilote,
- migrer par lots homogènes,
- tester les sauvegardes,
- surveiller la performance dans la durée,
- ajuster les ressources et documenter les procédures.
Une migration cloud réussie se distingue moins par le choix d’un fournisseur que par la qualité de l’analyse préalable, la rigueur de l’exécution et la capacité à intégrer les retours d’expérience.
Questions fréquentes sur la migration cloud
La migration cloud est-elle forcément totale ?
Non. La majorité des entreprises adoptent une approche hybride, où certaines briques restent on-premise et d’autres migrent vers le cloud, en fonction des usages et des contraintes.
Une migration cloud permet-elle toujours de réduire les coûts ?
Pas systématiquement. Elle permet en revanche de mieux les piloter, à condition de mettre en place une gouvernance FinOps minimale : suivi des consommations, ajustement des ressources, arrêt des environnements inutiles.
Faut-il changer d’outils pour migrer vers le cloud ?
Pas nécessairement. Certaines applications peuvent être réhébergées à l’identique, tandis que d’autres seront modernisées ou remplacées par des services SaaS. Le choix dépend du contexte métier et de la dette technique.